
I hope this article will give you the power to make the first step out of the continuous confusion we all live on the internet and in our lives by showing you what factual information is and how we can get to it with the help of computers.
Reading time: essentials 10 minutes; ~30 minutes reading to 1 hour on collateral and understanding
Articles related to this article:
Fact Fiction and The Truth
Fact Fiction and BS
You’ll find a precise definition of the notion of Fact and some of the technologies we can use to produce them. I’m using the term “Real Fact” to distinguish between the current notion of Fact as you can find in a dictionary and the notion I’m defining in this article. Though they are mostly the same as our general idea of Fact, they differ fundamentally in how are defined and created. In this article, each time (other than this text block) ‘Fact’ is the same as ‘Real Fact’.
WARNING! The technology and applications necessary to make this available to everyone is not yet built. The components (like Lego pieces) exist and are already in use but are not put together in the right way. This article aims to show you what can be done so that you’ll know what to look for and ask the industry to build for you. Yes if there is profit to be made the industry will build it. You simply need to show you want to pay for it.
In the context of this article, and hopefully in general if most of us will agree, the definition of factual information or simply ‘Fact‘ is as follows:
A fact is any packet of information that a receiver, human or machine, can inquiry and verify the following additional information components also called meta-information (or metadata).
The information packet and its associated meta-information represent a factual packet of information and they must be used together at all times.
The factual meta-information
- The complete description of the method (process, algorithms) used to produce the substantive information packet by measuring it directly from the real world
- The proof that the information and metadata was not changed or tampered with
This is,a piece of information used as a verifiable proof of the measured information integrity against any type of tampering or change in both its temporal (packet chain integrity) and a-temporal structure by any individual or machine at any moment in the future - The spatio-directional-temporal coordinates of the sensor device producing the information packets
- The digital identity of the sensor that produced the information
(not the owner, only the device)
The above definition enables the creation of very precise (mathematical level) models, algorithms, and devices able to produce factual information validated and trusted by both individuals and groups of individuals. The main condition (both important and challenging) is to ensure that the individuals receiving the factual information understand how was produced and protected in order to establish its level of trust. This requires training and it is the future notion of “literacy”.
Level of Trust for information
| # Level | Measurement Method | Measurement Integrity | Data Integrity |
| 0 | unknown | unverifiable | unverifiable |
| 1 | known | unverifiable | unverifiable |
| 2 | unknown | verifiable | unverifiable |
| 3 | known | verifiable | unverifiable |
| 4 | unknown | unverifiable | verifiable |
| 5 | known | unverifiable | verifiable |
| 6 | unknown | verifiable | verifiable |
| 7 | known | verifiable | verifiable |
Social Penetration Level
- Individual
When the fact-metadata is accessible and can be verified by a single individual usually the owner of the sensorial system (example: the pictures and video on your own phone) - Group
When the fact-metadata is accessible and can be verified by all members of a group (human or machines). This include also the group’s members participation in creating data integrity metadata (example: sharing pictures and data from your phone in a Face-Book group) - Global
When the fact-metadata is accessible and can be verified by anyone (public information). The anonymous public swarm will also provide redundant data integrity metadata (example: tweeting your pictures or video from your phone to the public)
A proposed symbolic representation of information trust and penetration levels
Based on the Trust level and social penetration level we can classify information and use a short notation such as ‘I’ (information) followed by one digit as its trust level then followed by the social penetration level as one digit.
For example, I01 is basically, with some exception, all the information one individual posse today. an I7x would be any factual information packet and in this case, we can simply use ‘F’+its social penetration level so F1 will be any factual information an individual has. So finally the F3 information piece can be simply called ‘Fact‘.
Some of the existing technologies that when combined can be used to produce factual information (though some are optional or interchangeable)
- HSM – or Hardware Security Module
- Enhanced security (by HSM) Digital Sensors
- Cryptography (symmetrical and public key cryptography)
- Trusted Digital Timestamp
- Block-Chain
- Classic digital machines (computers, smartphones,dedicated systems)
- Digital Crowd Anonymous Witnesses (TBD)
Questions you will need to ask and get answer to in order verify if a piece of information is factual or not
- Do I know how this information was produced (measurement method)?
- Can I verify if the measurement method was accurately followed?
- What is the error margin of the measurement process (calibration)?
- How do I verify if the information produced by the sensor is what I received?
(was it changed?)
Let’s get practical
A combination of the technologies listed above can be used to produce both trusted sensor systems as well as applications/libraries that a receiver can use to classify the information trust level. Basically to obtain an Fx (string representation of the information trust level).
Example 1 Social media: A smartphone able to produce factual information (video for example) that you can upload on YouTube and anyone else can verify its trust level. More, if the image or video was edited or filtered you should be able to ask the computer to show you what parts (pixels, etc) of the picture or video are factual and the ones transformed and be able to obtain the original raw sensed information.
Example 2 news: You read an article or watch a video on the net or TV, if this technology is available you should be able to ask the computer to tell you what is factual and what is not.
Factual implementation difficulty levels depends on their social penetration level
F1 – or “Personal Facts” is the entry level and most accessible
The F1 fact level is information that you are in full control of how you sense it (measure/capture) and ensure its integrity. You may ask yourself why should you protect your own data? From whom? Well, other people may have access to your data directly (you trust them) and change it by mistake or with malicious intent or your machines can break or bugs in your code act on and change your data. Intruders can also change pictures, video,s etc files you own. How can you be sure this did not happen for data you did not access for months or years?
The difference between F1 and the other levels is only in how large is the group that needs to have a shared trust in that data is and for F1 it is only you. Obviously, once you try to share your info with others you’ll need an F2 or F3 fact level so the others can also trust it.
The good part with F1 is that if you know enough about computers and programming you can create your F1 level information almost immediately. However, without an HSM to protect the sensing process, you’ll never be able to elevate the level of that information to an F2 or F3 level.
F2 – or closed group factual information — Group relative facts
F2 level will be used mostly by businesses that are big enough to afford to create their own sensing platforms with HSM-protected sensors and data integrity ensured by rules accepted by that group. The issue with F2 is that without full transparency and verification in how the sensors are built and data integrity is ensured F2 can’t be upgraded to F3 (full factual).
F3 – or ‘full factual’/’public fact’ information
F3 is the most challenging type of factual information though in time with global collaboration will be possible to create. To create F3 we need full open-source sensors design and codding and open, fully automated (full hands-off) build process that can be verified by the public at large (everyone on Earth). Additionally, anonymous crowd-based and redundant processes must be used for data validation. Machines participating in the “witnessing” process must also be built in the same open transparent way as the sensors.
You can probably call this the fishbowl strategy. We can only get out of our current confusion by helping each other.
The special case of news and established media and arts
The written word always had a “weight” in trust compared to the “spoken” word. Before Gutenberg built and used its first presses to lower the cost of producing copies of information on paper, writing a book was a very expensive and highly custom and artistic endeavor. Since the support of the information (the book) was so expensive, strong due diligence was done in verifying the information put in those books.
The price of the books also created an “investment/sunk cost bias” in both scribes and owners of the books leading to higher levels of trust. One may say that those books can be trusted better than today’s information which is mainly effortless to produce and disseminate. I would caution you to check on that trust. Check the old and expensive books that say Earth is flat and let me know if you still trust them without a hitch. The problem is that due to all those biases the old books were in fact a higher risk to disseminate falsehood exactly because most people had no intention to check their content.
Consequences? Well, just look at the “Witch hunts” that hurt and destroyed so many innocent lives in our past. They were all fueled by a few of those expensive books that no one dared to oppose until the higher-ups started to get hurt.
So, if the price of the book is not a guarantee of its “factuality”, what can we expect of the current cheap, click-driven article writing? Well, you can check for yourself at any time out there on the “open wild” net.
By the way, this does not mean all news out there is unreliable or fake, it simply means that you have no real way to verify if a piece of information is factual or not. It is just darn hard to do it and that means that for regular people it is impossible to tell fact from non-fact.
The proposal in this article can rebuild the trust and raise it to levels never found before once you will be able to verify every word, sentence, image, or video in the same effortless way you can produce your own factual information.
This can truly change from the ground up the news business battered currently by confusion among readers. In this business model news companies will not produce the news themselves but simply work as hubs for aggregation, analytics, and interpretation of factual event streams produced by sensors owned by all people on Earth. At that point, it may even be a “conflict of interest” for news businesses to produce their own input data, a huge difference from how they currently work.
On the other hand, arts and fiction storytelling can thrive like never before because the readers will be able to verify what is art and fiction in any end product. The artist or writer can be free of BS dissemination once the recipients of their work will be able to tell what is fact and what is imagination.
Science
In the human quest for a better life, the knowledge about how this reality really works is one of the main pillars holding us from slipping into the dark abyss of nothingness. Science is the process of finding the elusive causal relationships we can trust from the pile of correlation-driven events the reality throws at us.
It is a tricky and difficult process that uses imagination (fiction) to try to find the causality then pin it down with models backed by measurements. The measurements done in scientific experiments differ from the non-scientific ones by the way scientists keep a clear description of the measurement methods and by peer review other scientists can validate the integrity of the method of measurement and the data. In a few words, scientists are aiming to produce factual information.
Scientists can benefit from being able to produce factual information with ease, as they will not need to fight to prove that their experimental information is factual. Peer reviews and experiment reproduction still need to be done however since the initial measurement method is clearly defined it makes it easier for more people to review or retry various experiments.
Science experiments can cost billions of dollars if we are talking about CERN-like setups or no cost at all if the test is to check the theory that a slice of bread falls more frequently on the buttered side. They all can benefit from this method and technology of factual sensorial devices.
DNA sequencing healthcare and pandemics
Just imagine how much better our entire civilization would have responded to the #COVID19 pandemic or any other pandemics if each of us would be able to record facts about ourselves and securely and anonymously share this info with everyone else. The pandemic would have been quashed in weeks if not days and so many lives would have been saved and basically, none of the businesses would have been impacted.
Since we are talking about digital sensors and pandemics please take a look at the Nanoporetech technology as it holds the key for a completely new way to deal with microscopic life such as viruses and bacteria. Their sensors are not yet backed by HSMs and do not produce factual DNA data streams (as described in this article) but they can in the future.
When that will be possible and the cost of a scan will drop to less than a lunch we will be able to use it to keep an eye to the micro-world at a daily basis without lifting a finger. This means that the notion of healthcare will be forever changed. The difference between what we have now and that potential future is same or more than between the current healthcare and the one Galileo had on his time.
The justice system, the law and law enforcement
If the scientific method is fully dependent on factual information the Justice Systems should see the factual information as a must-have if innocents are to be spared from wrong charges and convictions.
Since smartphones are in almost everyone’s pocket we witnessed so many episodes when the people we pay to keep us safe forgot completely what their mandate was and broke their oaths toward society by unnecessarily hurting or even killing people they swear to keep safe.
In this domain, factual information is as important as oxygen for life. All the mojo of any trial is to reveal the facts first then based on them and only on them make decisions that are aimed to fix what was broken. Yet now we know that since facts are scarce or even nonexistent the Justice System is unable to get it right in too many cases.
When the Justice Systems (even the democratic ones) make mistakes and punish the innocents there is a double whammy, we hurt people that are innocent and prove to the criminals they can get away with it and continue to do what they did before.
I hope you can see how factual information produced as described in this article can help improve the inner workings of any Justice system and help the innocents.
Measurements and Information
(WARNING! this is just hypothetical)
When talking about factual information we also need to understand the information that is not factual. One example is the information that can’t be precisely measured and we call imagination. What is imagination? How does it relate to factual information?
Though the following hypothesis its just that a hypothesis it can be used to define the factual (real) information or the domain of extra-factual or imagination.
When we the people started to dig down in the domain of microcosm we found something that suggests that there are things we call real, that we can “feel” and measure (the feeling is a form of measuring) and something else that exists before measuring process that can’t be called “real”. We modeled these behaviors under a mathematical framework called Quantum Mechanics (QM).
For me personally, the space-of-states outside of “the real” are part of an entity “larger” than the real (or realized) space-of-states (our universe) from where the real states are created via a process we call “measurement”. I’ve labeled this Extra Outer Universe the “Exoverse”.
Without going into more detail in this article (more later) I hypothesize the existence of an additional field to the fields already postulated by the quantum field theory that could be called “consciousness”. It is (in my opinion) the one responsible for “exploring” the Exoverse by the same process we taped-in in our Quantum Computers, the superposition. The process of creating real states from potential states is a phenomenon our selves perceive as time.
The superposition is used (by the consciousness) to explore a chunk of the Exoverse testing various outcomes in many possible “futures” and creating real states once this process is done. This process also generates what we call time. I’m labeling this explored domain inside of Exoverse, the “Extraverse” and I believe it is an integral part of the process we perceive as “imagination”.
In this context, the Universal states are all connected in a DAG (Direct Acyclic Graph), and the Extraverse is made of a very large (but finite) number of loops (superposition internal behavior).
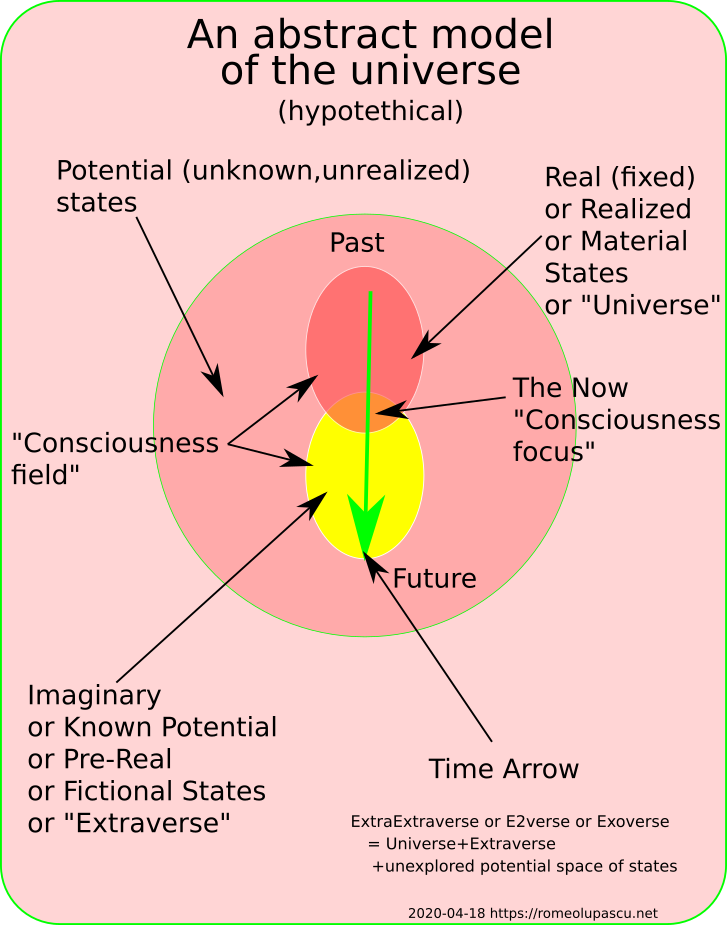
Based on the diagram above and this hypothetical structure of the Exoverse we can clearly define the Real (measurable and factual) from Imaginary (fictional, non-measurable) domains.
Obviously, people can communicate via speaking, writing, and art the information present in their minds describing states that do not exist in our reality and the act of communication itself can be considered as factual as it can be measured.
This issue can lead to confusion as one can “wrap” an imaginary piece of information in a factual “shell” and present it as a fact. That is why we need the method by which the measurement was done to be known and verifiable.
Just a reminder that the notion of BS in this context is “a mix of factual and imaginary information presented as a fact” (See Fact Fiction and BS article). I also find this book “Calling Bullshit: The Art of Skepticism in a Data-Driven World” an interesting work focused on the problem of BS.
Original article validation: here
Current article validation: here